
In recent years browsers have supported streaming HTML and JavaScript. In this article we will talk about the benefits of this, and what else we can do that browsers don't do automatically to take full advantage of streaming.
Streaming HTML
During the initial load, we don't have to worry much because the browsers do it automatically. When they receive the HTML chunks during the streaming they print the content.
To activate the streaming from the server you have to adapt the headers, for example:
{
"transfer-encoding": "chunked",
"vary": "Accept-Encoding",
"content-type": "text/html; charset=utf-8"
}
And in the response use a ReadableStream. This would be the example with Bun:
const encoder = new TextEncoder()
// ...
return new Response(
new ReadableStream({
start(controller) {
controller.enqueue(encoder.encode('<html lang="en">'))
controller.enqueue(encoder.encode('<head />'))
controller.enqueue(encoder.encode('<body>'))
controller.enqueue(encoder.encode('<div class="foo">Bar</div>'))
controller.enqueue(encoder.encode('</body>'))
controller.enqueue(encoder.encode('</html>'))
controller.close()
},
})
)
Each string inside enqueue is a chunk that the browser will receive.
Changing the HTML content during streaming
One of the practices that is being done a lot because it has many performance benefits is to change the HTML content during streaming. A clear example is React Suspense. The idea is to show empty content (placeholder, skeleton, or spinner) while loading the rest of the HTML and in the meantime, it is loading the missing content. Once the server has the missing content then in streaming-time it changes it!
Perhaps the first question that comes to your mind is how can you modify a part of the HTML that has already been sent and processed by the browser 🤔?
Well, browsers are smart enough to execute small JS scripts during streaming. However, they have to be scripts without being module type, because they always wait for all the HTML to be loaded before executing. In this case, we are not interested.
This would be an example to make it visually understandable (it's normally more complex than this):
return new Response(
new ReadableStream({
async start(controller) {
const suspensePromises = []
controller.enqueue(encoder.encode('<html lang="en">'))
controller.enqueue(encoder.encode('<head>'))
// Load the code to allow "unsuspense"
controller.enqueue(
enconder.encode('<script src="unsuspense.js"></script>')
)
controller.enqueue(encoder.encode('</head>'))
controller.enqueue(encoder.encode('<body>'))
// Add a placeholder (suspense)
controller.enqueue(
encoder.encode('<div id="suspensed:1">Loading...</div>')
)
// Load the content - without "await" (IMPORTANT)
suspensePromises.push(
computeExpensiveChunk().then((content) => {
// enqueue the real content
controller.enqueue(
encoder.encode(
`<template id="suspensed-content:1">${content}</template>`
)
)
// enqueue the script to replace the suspensed content to the real one
controller.enqueue(encoder.encode(`<script>unsuspense('1')</script>`))
})
)
controller.enqueue(encoder.encode('<div class="foo">Bar</div>'))
controller.enqueue(encoder.encode('</body>'))
controller.enqueue(encoder.encode('</html>'))
// Wait for all suspended content before closing the stream
await Promise.all(suspensePromises)
controller.close()
},
})
)
Where the unsuspense.js file is the one that exposes the window.unsuspense in this case so that it can be executed during the streaming and it replaces the content of the suspensed:1 by the content of the suspensed-content:1 template. In this case, the user will see the Loading... text and also the div with the Bar text. Once the content has been processed, the Loading... content will be changed to the real content.
Thinking of benefits, everything is done with a single request and the user instantly sees the HTML and the changes to it without having to make extra requests. In the past years, these requests were made from the client, for example in React using a useEffect, making this not executed until all the HTML was loaded, making another extra request to the server and complicating the life of the developers.
By being able to modify the HTML content during streaming, it now allows you to use async components and you can directly use fetch or make database requests in conjunction with Suspense.
HTML Streaming in runtime
We have talked about the practicality of HTML streaming for the initial loading of HTML, but apart from the initial loading, are there other scenarios where we want to stream HTML?
Yes, there are two cases:
Navigation (View Transitions API)
Since 2023 Chrome announced the View Transition API, and it looks like Safari is also going to support it soon.
The View Transitions API provides a mechanism for easily creating animated transitions between different DOM states simulating single-page apps (SPAs) while also updating the DOM contents in a single step.
During navigation, we usually want to replace all HTML content with other content. However, we must take advantage of streaming so that we don't have to wait.
window.navigation.addEventListener('navigate', navigate)
function navigate(event) {
const url = new URL(event.destination.url)
const decoder = new TextDecoder()
// Only intercept navigations within the same origin for security
if (location.origin !== url.origin) return
event.intercept({
async handler() {
const res = await fetch(url.pathname)
// Creates a new "sandbox" HTML Document
const doc = document.implementation.createHTMLDocument()
const stream = res.body.getReader()
// Transition to the new document with smooth scrolling
await document.startViewTransition(() => {
// Connect the current document's DOM with the sandbox's DOM
document.documentElement.replaceWith(doc.documentElement)
document.documentElement.scrollTop = 0
}).ready
// Process the response body in chunks
while (true) {
const { done, value } = await stream.read()
if (done) break // Exit the loop when the stream is finished
// Inject decoded content into the sandbox document
// within a transition. The sandbox treats the string and
// parses it, then during the transition it is put into the
// real DOM.
await document.startViewTransition(() =>
doc.write(decoder.decode(value))
).ready
}
},
})
}
In this example, document.implementation.createHTMLDocument is used in conjunction with doc.write to process the stream, making each chunk a different transition. The use of doc.write should not raise an alert, in this context, it is well used. For more details of this trick this Chrome's video explains it.
The above example serves only to replace all HTML content with other content, but what if we wanted to have more control over the HTML nodes during streaming? Perhaps to filter out specific nodes during this streaming.
To make this possible, we can use the parse-html-stream library to make it easy to transform a stream reader to an HTML node generator. In this case, we could use it like this:
import parseHTMLStream from 'parse-html-stream' // Import it
window.navigation.addEventListener('navigate', navigate)
function navigate(event) {
const url = new URL(event.destination.url)
const decoder = new TextDecoder()
if (location.origin !== url.origin) return
event.intercept({
async handler() {
const res = await fetch(url.pathname)
const doc = document.implementation.createHTMLDocument()
const stream = res.body.getReader()
await document.startViewTransition(() => {
document.documentElement.replaceWith(doc.documentElement)
document.documentElement.scrollTop = 0
}).ready
// Use it:
for await (const node of parseHTMLStream(reader)) {
// You have full control of each HTML Node during the streaming
console.log(node.nodeName)
}
},
})
}
However, it is much more complex now to implement adding the node in the right place in the main document, isn't it? So does all this make sense?
To understand the benefit of this, read on.
RPCs (ex: server actions)
A remote procedure call (RPC) is used so that developers do not have to implement an endpoint and all the communication logic between browser-sever and server-browser is handled by the RPC. An example of RPC would be React server actions, which can trigger updates to the DOM during streaming. However, React here is using a virtual DOM instead of transferring hypermedia (HTML) and using the diff algorithm with the real DOM.
In this article, I will not explain the technical details of how to implement an RPC, but to understand how server actions would work in a different context than React, I invite you to watch this video with an example of making events like onClick work on server components, i.e. when the user clicks a button in the browser, then the onClick function is executed on the server.
Reactive server coming soon 👀 pic.twitter.com/eZSHvVUPO4
— Aral Roca (@aralroca) February 1, 2024
The video of this tweet is about an experimental framework I'm doing, I hope in a few months to make it public and give more details.
The grace is that from the server you can modify the DB or whatever you want and see the HTML changes reflected in the browser.
rerenderInAction 👀 pic.twitter.com/ZfxQqpR8fz
— Aral Roca (@aralroca) February 20, 2024
To make this possible, from the RPC client code (200B) a request is made to the action and if it is the first time, another request is made to download the lazy client code (1 kb) to process the response. This last code will be responsible for processing the HTML and updating the DOM only for the parts that have changed using the DOM Diffing algorithm.
To show you the benefit of this, think that you could build a SPA with almost no JS on the client, just the RPC. However, server actions make sense for interactions that involve server. For purely client interactions or that you need the Web API then you can use web components.
Another benefit of updating only the modified parts of the DOM, instead of the entire DOM, is its excellent integration with Web components. Web components, particularly those utilizing signals to react to changes, can maintain their internal state without losing synchronization.
DOM Diffing algorithm
React to update the Document Object Model (DOM) uses the diffing algorithm but with a virtual DOM, so it transfers the virtual DOM instead of hypermedia (HTML) directly. It does this to have more control over the client components since they are not reactive to the DOM. On the other hand, if our client components are web components with signals their properties are reactive and if the element is updated by adding a new attribute, then the web component without losing its internal state will react to the changes. This allows us to transfer directly HTML and work directly with the DOM.
Currently there are several open-source DOM diff algorithms, some examples:
Most implementations use breadth-first search to traverse the DOM tree and update it.
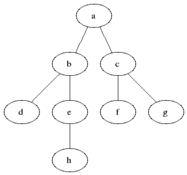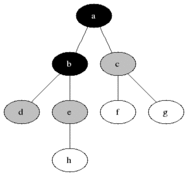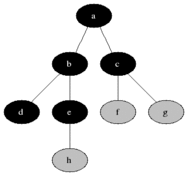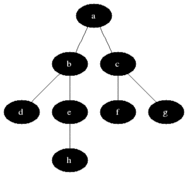
However during HTML Streaming the nodes arrives as depth-first search (DFS):
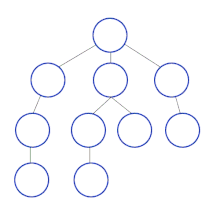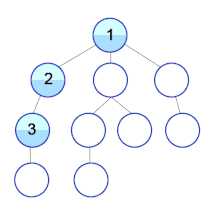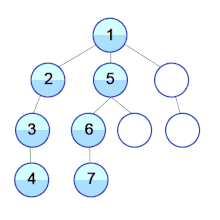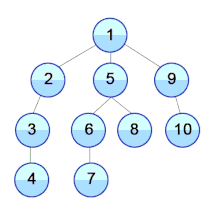
If the server can start sending HTML as soon as possible and the browser does not wait for the entire response to arrive, it can process the HTML code in fragments as it arrives.
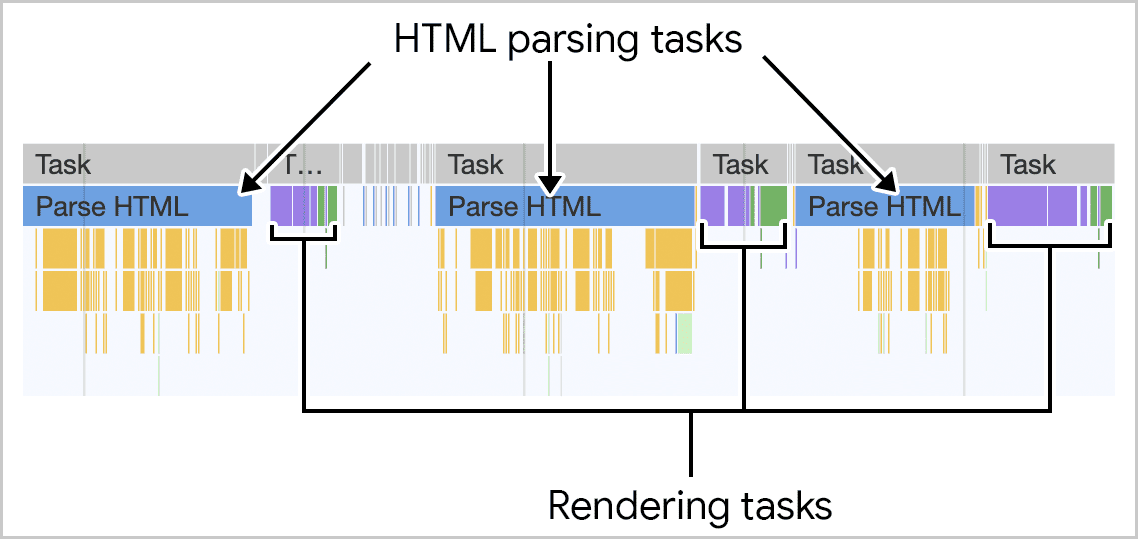
The last image is how browsers process streaming HTML, but the same must be done to support the DOM Diffing algorithm for streaming.
The rendering work is incremental to present the page changes to the user as quickly as possible. This approach generates a better Interaction to Next Paint (INP) score for the page.
Even the chunks arrive in DFS order, the browser cannot render an element until it has received all the information that defines it.
If you remember, when we talked about navigation, we gave an example that did the following:
for await (const node of parseHTMLStream(reader)) {
// You have full control of each HTML Node during the streaming
console.log(node.nodeName)
}
At this point, the nodes always arrive in DFS order. But it is not enough, because we need to walk through the tree inside the DOM diffing algorithm. That is, visit the firstChild, nextSibling, the parentNode, etc, and compare it with the real DOM nodes.
To do this, the parse-html-stream library that I have recently put in open-source, supports also walking through the tree of nodes during streaming, allowing you to do incremental rendering, while you walk through the tree the library is parsing the HTML chunks in the order they arrive, and while you have the parsed nodes you are making the rendering changes.
import htmlStreamWalker from 'parse-html-stream/walker'
// ...
const reader = res.body.getReader()
const walker = await htmlStreamWalker(reader)
// Root node
const rootNode = walker.rootNode
// Gives the firstChild taking into account the stream chunks
const child = await walker.firstChild(rootNode)
// Gives the nextSibling taking into account the stream chunks
const brother = await walker.nextSibling(rootNode)
// You can do it with every HTML node:
const childOfBrother = await walker.firstChild(brother)
In this case rootNode, child, brother, and childOfBrother are Nodes and you have access to all Node properties. Note, however, that there are two properties that may not be true because streaming chunks have yet to be received:
node.firstChild❌ - Stop being correct, in some cases, it would work, in others it would not because maybe the next chunk is the child of the Node.node.nextSibling❌ - Stop being correct, in some cases, it would work, in others it would not because maybe the next chunk is the sibling of the Node.
For these cases, the parse-html-stream walker offers two methods to replace them so that they always work:
walker.firstChild(node)✅ - Try first to get thefirstChild, if not yet wait for the next chunk to verify if it has it or not. When the next chunk arrives it processes the next nodes.walker.nextSibling(node)✅ - Try first to get thenextSibling, if not yet wait for the next chunk to verify if it has it or not. When the next chunk arrives it processes the next nodes.
The initial nodes do not lose context and can be used after the execution of these functions.
Conclusions
In the article, we talked about the benefits and practical applications of HTML Streaming beyond just the initial rendering.
We talked about more technical concepts such as RPC, View Transitions API, DOM Diffing algorithm, but without going into detail on each of these topics, but rather how to use HTML Streaming in each of them. If you are interested in knowing more about topics that I have not gone into depth in this article, comment it in the comments and I will take it into account to make another article focusing on other topics that interest you.
We have also talked about parse-html-stream, a small library that I have recently put in open-source so that anyone can use it.
On a final note, the web was invented to transfer hypermedia (HTML) and after using JSON and a lot of client code over the last years, I hope to see more Hypermedia-Driven applications available to make life easier for developers and make websites lighter with almost no JavaScript code, so I see great promise for the future of HTML streaming beyond the initial load.
References
- https://bun.sh/docs/api/streams
- https://react.dev/reference/react/Suspense
- https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model
- https://github.com/aralroca/parse-html-stream
- https://web.dev/articles/client-side-rendering-of-html-and-interactivity
- https://htmx.org/essays/hypermedia-driven-applications/
- https://en.wikipedia.org/wiki/Depth-first_search
- https://en.wikipedia.org/wiki/Breadth-first_search
- https://github.com/patrick-steele-idem/morphdom
- https://github.com/DylanPiercey/set-dom
- https://diffhtml.org/
- https://github.com/fiduswriter/diffDOM
- https://github.com/choojs/nanomorph
- https://google.github.io/incremental-dom/
- https://demystifying-rsc.vercel.app/static-content/2/



